In this post I define the concept of "hardware completeness" and show its relevance to the design of programming languages and compiler IRs.
Definition of hardware-completeness
Let's say a programming language or compiler intermediate representation (IR) is "hardware-complete" on hardware platform X if you can use it to generate code that's equivalent to any valid machine code program for platform X. For our purposes, "equivalent to" measures both functionality and performance.
Some examples of hardware-complete languages are:
- C (if you include inline asm or hardware-specific intrinsics),
- CUDA C++,
- PTX, Nvidia's high-level assembly language for their GPUs,
- LLVM IR, and
- x86 assembly code (an x86 CPU is an x86-asm-to-microcode optimizing compiler implemented in hardware).
Of course, you can't always get 100% of the performance of handwritten machine code out of, say, a C program—at least, not without replacing your whole program with a giant block of inline asm (although I'd argue the fact that you can do that is part of what makes C hardware-complete). But philosophically, hardware-complete languages try to make it possible to get close to "100% performance", and if you can't, it's probably a bug.
In the world of machine learning, we have many languages and compiler IRs which are not hardware-complete. Some examples of hardware-incomplete languages for ML are:
These are incomplete because there are many valid CPU and GPU programs that you cannot write using these languages. Even if the language is Turing-complete so you can always get functional equivalence, it would often come at the cost of a huge slowdown compared to handwritten assembly (or C).
Implications of (in)completeness
Using the word "incomplete" might make it sound like a bad thing, but hardware-incomplete IRs have many benefits, including:
Incomplete languages usually target a specific domain (e.g. ML) so (hopefully!) it's more pleasant to write domain-specific code in one of these languages than a complete/general-purpose language.
Incomplete languages usually have restrictions that make it easier to do compiler optimizations.
It's easier to make incomplete languages portable to different hardware, because you're not aiming to generate any valid program on the target hardware. (For example, LLVM IR is not actually portable; you can't take LLVM IR generated for x86 and expect to run it on a GPU.)
But one negative property about incomplete IRs is, it's hard to translate from one to another. That's because in order to translate from language A to B, all machine code programs that can be generated by A must be generateable by B, and with roughly-equivalent performance. This works by definition if B is complete, and usually doesn't work if B is incomplete. And even if it works at any one point in time, incomplete languages are always changing (because you are always finding new programs you want to generate), and it's vanishingly unlikely that they will change in the same way and at the same pace.
For example, although XLA, ONNX, and TensorRT all try to cover roughly the same subset of valid programs on nvidia GPUs, in practice they do not overlap perfectly, so it's not possible to translate an arbitrary XLA program to ONNX or TensorRT.
Another fact is, because XLA, ONNX, and TensorRT all try to cover roughly the same subset of GPU programs, they look very similar. So similar you might be able to convince yourself that you can translate between them. And you'll be able to get 90% of the way there before you understand the differences well enough to realize how doomed you are.
Of course, if a programming language is designed around the limitations of an incomplete IR, that can work. For example, JAX (originally, "Just Another XLA") is designed around the limitations of XLA, so it can lower to XLA without issue. But it would be hard to lower JAX to a different incomplete IR with slightly-different limitations. Indeed many incomplete IRs have their own dedicated language. For example, the Triton language is tightly coupled to Triton's IR.
Conclusions
The above was just definitions and facts. What can we conclude from it?
Upshot 1: As an ML compilers person, I frequently have the following conversation with hardware people.
Them: We have developed a new IR and compiler for machine learning. We will take your IR (XLA, Triton IR, whatever) and lower it to our new IR. Then all of your programs will get great performance on our hardware.
Me: Thanks but no thanks. I won't be able to lower all Triton programs to your IR.
Them: I don't understand, you lower XLA/Triton programs to LLVM IR today, right? What's the difference?
The fundamental problem is that the hardware person is asking me to lower my incomplete IR to another incomplete IR. For the reasons above, this is unappealing and probably won't work.
Upshot 2: If you're designing an incomplete IR, I'd say you probably should design a programming language to go with it. This way you can enforce your IR's limitations at the level of user code, instead of having performance and functionality cliffs that are unpredictable to your users and that depend on which compiler backend they're using. I think this tight coupling between language and IR may be one of the reasons JAX and Triton have been so successful.
A corollary of this is that your incomplete IR probably won't be relevant unless its associated programming language is successful. At which point, you should probably think about the programming language first and the IR second.
Upshot 3: This also explains my skepticism of "ML compiler hourglass diagrams". Behold.
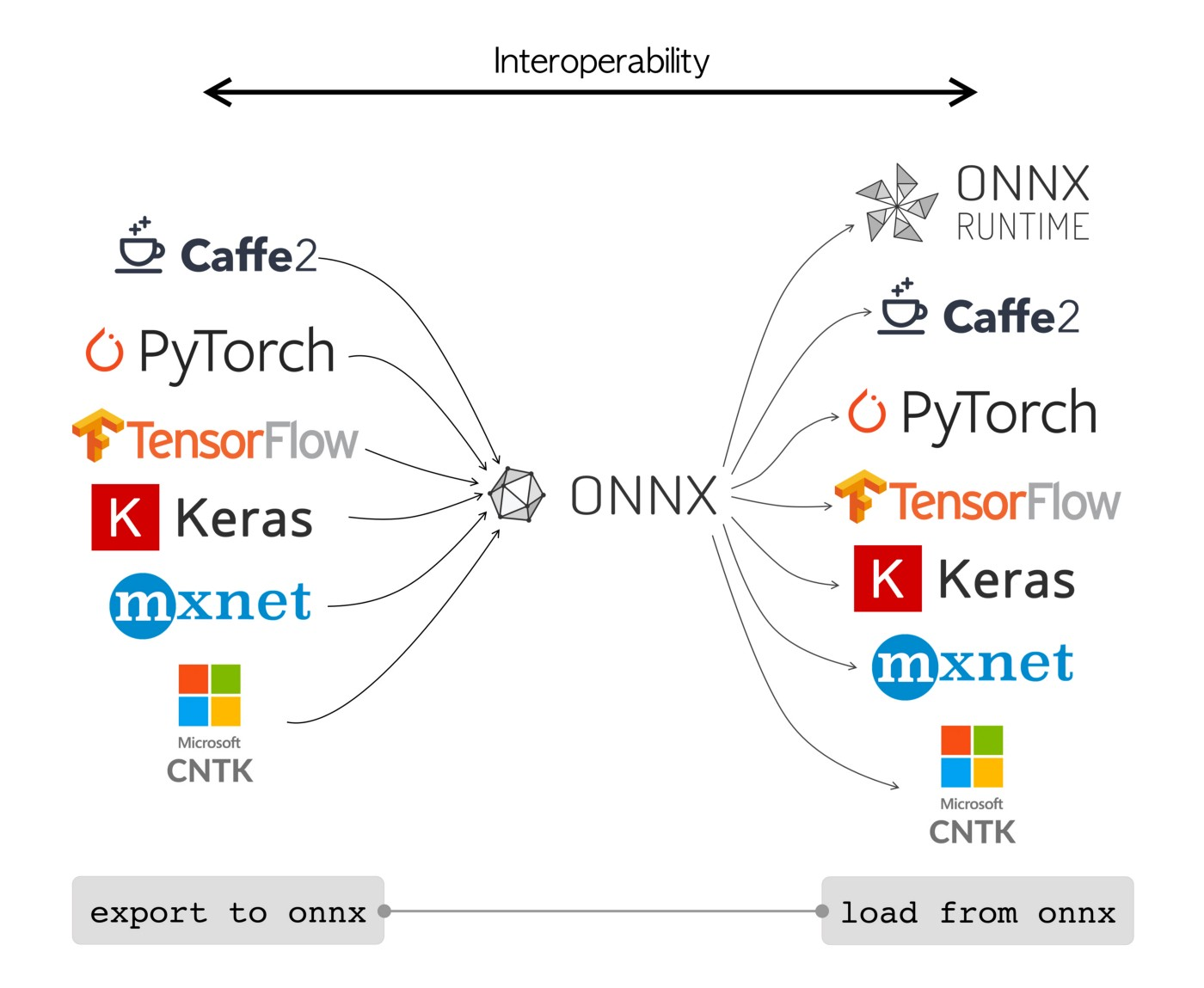
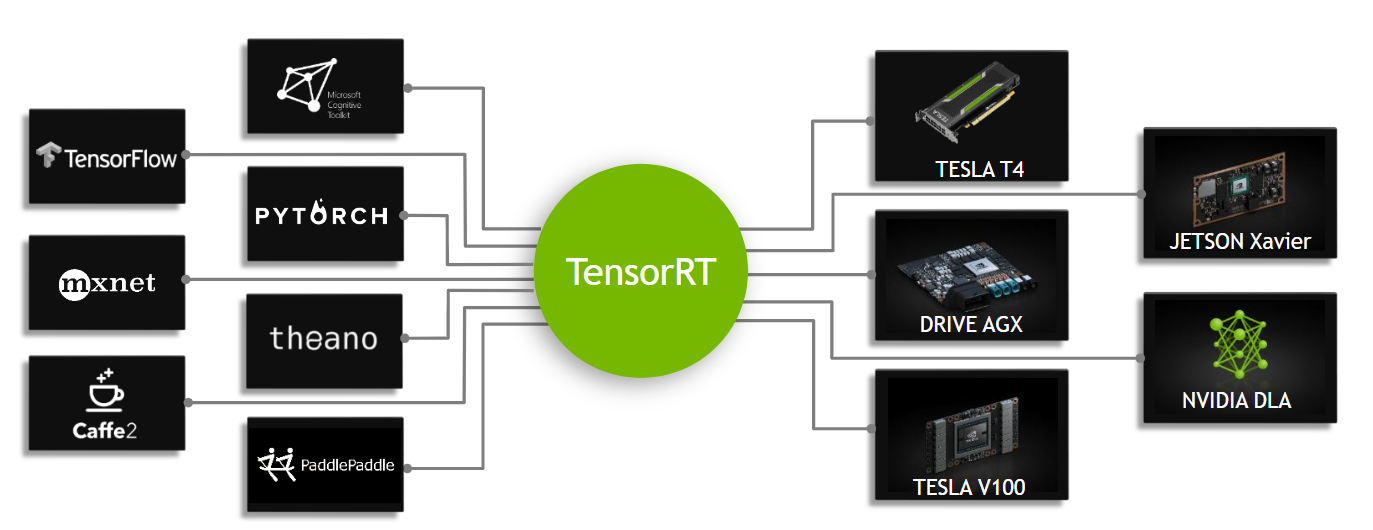
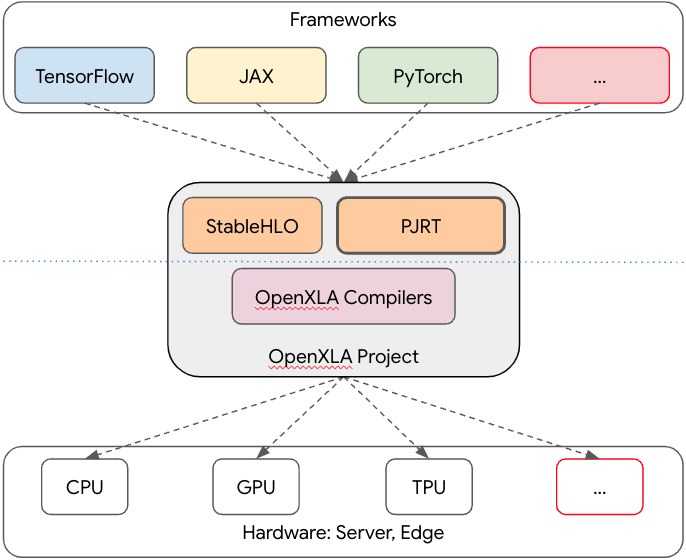
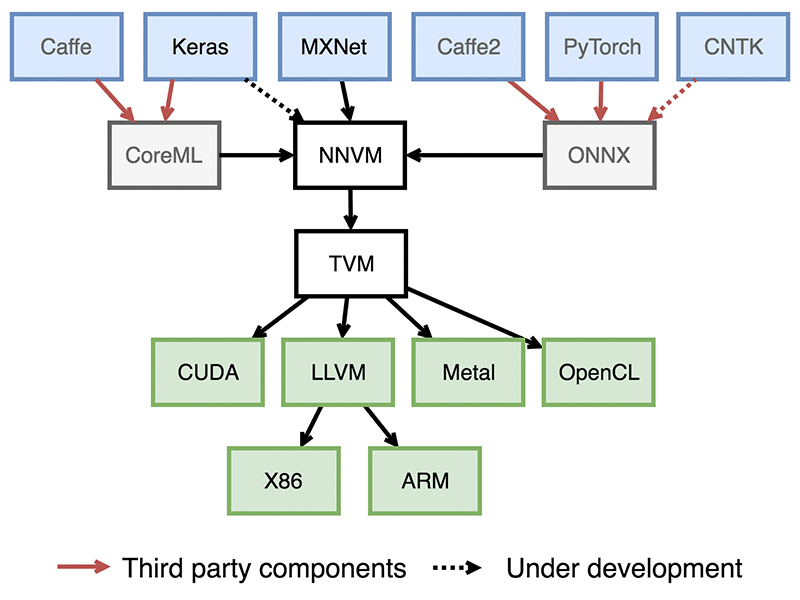

In all of these cases, the narrow part of the hourglass is an incomplete language, so it has all the problems I've described above.
Thanks to Kyle Huey and Mehdi Amini for feedback on drafts of this post.